The MSP-Podcast Corpus
This is a database created by the Multimodal Signal Processing Laboratory at The University of Texas at Dallas. The principal investigator is Prof. Carlos Busso.
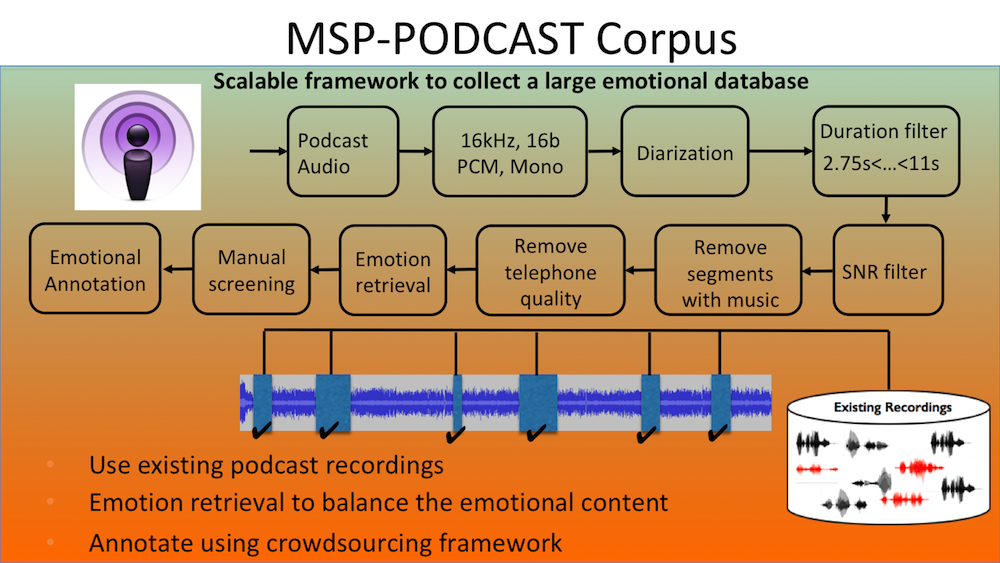
We are building the largest naturalistic speech emotional dataset in the community. The MSP-Podcast corpus contains speech segments from podcast recordings which are perceptually annotated using crowdsourcing. The collection of this corpus is an ongoing process. Version 1.8 of the corpus has 73,042 speaking turns (113hrs)
This corpus is annotated with emotional labels using attribute-based descriptors (activation, dominance and valence) and categorical labels (anger, happiness, sadness, disgust, surprised, fear, contempt, neutral and other). To the best of our knowledge, this is largest speech emotional corpus in the community.
I have been leading this effort since Fall 2017. Since then, we have released 8 versions of the database to various industrial corporations and academic labs. This is now available under both commercial and academic licenses. Please visit our lab website to learn more about the corpus and how to acquire it.